Causal Concept Embedding Models: Beyond Causal Opacity in Deep Learning
New preprint released: “Causal Concept Embedding Models: Beyond Causal Opacity in Deep Learning”!
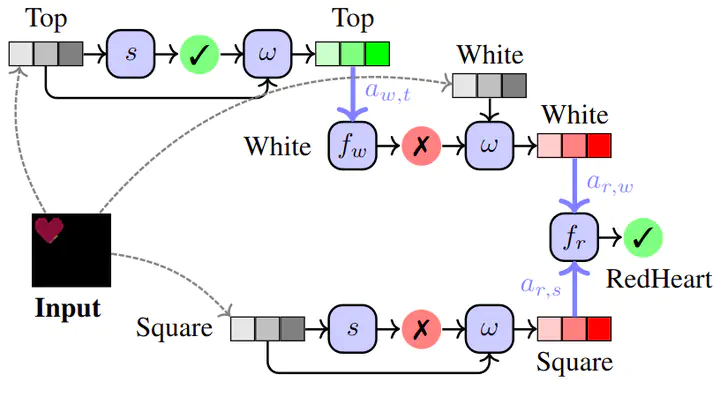
Abstract Causal opacity denotes the difficulty in understanding the “hidden” causal structure underlying a deep neural network’s (DNN) reasoning. This leads to the inability to rely on and verify state-of-the-art DNN-based systems especially in high-stakes scenarios. For this reason, causal opacity represents a key open challenge at the intersection of deep learning, interpretability, and causality. This work addresses this gap by introducing Causal Concept Embedding Models (Causal CEMs), a class of interpretable models whose decision-making process is causally transparent by design. The results of our experiments show that Causal CEMs can: (i) match the generalization performance of causally-opaque models, (ii) support the analysis of interventional and counterfactual scenarios, thereby improving the model’s causal interpretability and supporting the effective verification of its reliability and fairness, and (iii) enable human-in-the-loop corrections to mispredicted intermediate reasoning steps, boosting not just downstream accuracy after corrections but also accuracy of the explanation provided for a specific instance.
Link ArXiv
Pietro Barbiero
Research Assistant
AI researcher with 5+ years of experience in deep learning, interpretability, and neural symbolic AI.